过去几年,北美客户服务市场如火如荼,我们不仅在软件领域见证了众多独角兽、十角兽以惊人的速度诞生;
人工智能与机器学习的应用越来越普及,慢慢的变成了众多传统公司提升效率和收入的关键。中国的云服务市场和客户服务市场尽管尚在早期,我们也已经欣喜地看到慢慢的变多优秀的公司和团队在数据基础设施领域崭露头角。
A16Z在20年和21年分别发表了2篇关于现代数据基础设施架构的文章,探讨和分析了基于分析系统和业务系统的三种通用架构图,对于数据基础设施领域能否出现平台型公司也进行了讨论。他山之石,可以攻玉。我们推荐对数据基础设施领域感兴趣的创业者阅读、思考,与我们进一步交流。
在企业服务市场上,众多高价值的软件公司的出现已经证明了他们非常擅长构建大型复杂的软件系统。最近,我们也开始看到围绕数据构建的大规模复杂系统的迅速增长。该系统的主体业务价值来自于数据分析,而非来自于软件。这一变化趋势开始迅速影响整个行业,包括新职位的出现、客户采购的变化、以及围绕数据提供基础设施和工具的初创公司的出现。
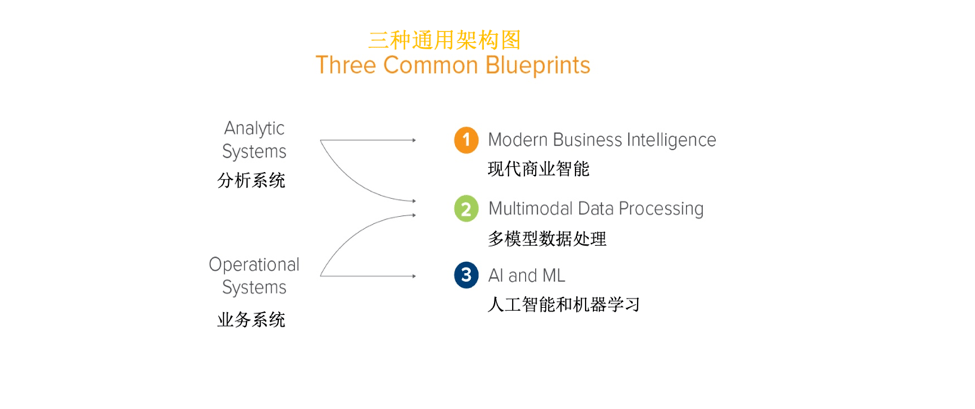
众多快速地增长的基础设施初创公司都在围绕数据管理系统研发产品。这些系统能分为两类:一类是支持数据驱动决策的系统,我们称为分析系统。另一类是支持数据驱动产品,包括机器学习在内的系统,我们称为业务系统。这类数据管理产品有了从数据传输管道、数据存储解决方案到分析数据的SQL引擎、数据看板等涉及数据科学、机器学习库、数据管道自动化和数据目录等众多领域。
然而,尽管增长势头迅猛,我们得知大多数人对于哪些技术处于领头羊以及如何在实践中使用它们,任旧存在诸多困惑。在过去的2年中,我们与上百位创始人、数据部门负责人和相关专家 — 包括20多位深度参与正被普遍的使用的数据技术栈的一线人员进行了深入交流,试图为大家描绘我们不难发现到的最佳实践,并围绕数据基础设施统一通用名词以便交流。这篇文章将与大家伙儿一起来分享我们的工作成果,并展示这些推动行业向前发展的技术极客们。

本报告及数据基础设施架构图汇集了数十名从业人员的心血智慧。在此一并致谢:
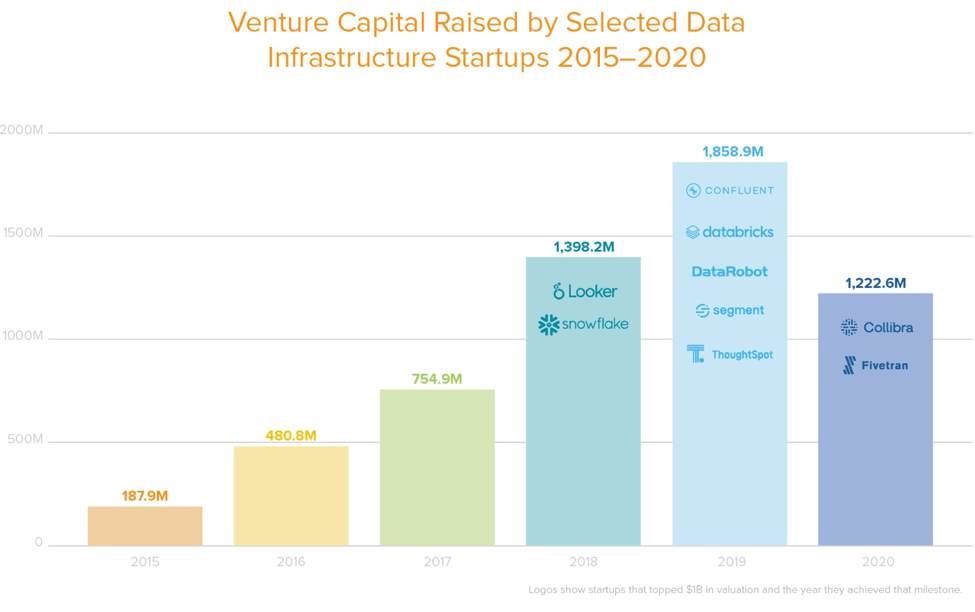
过去几年,数据基础设施领域的快速地增长是我们撰写这份报告的重要推动力之一。根据Garnter的统计,2019年,企业在数据基础设施领域的支出达到660亿美金的历史高点,占所有基础设施软件支出的24%,且还在持续增长。根据Pitchbook的统计,在过去的5年里,TOP30的数据基础设施初创公司的融资额高达80亿美金,估值总额达到350亿美金。
数据相关的竞争也映射到了求职市场。数据分析师、数据工程师和机器学习工程师位列Linkedin 2019年增长最快的职位列表。根据New Vantage Partners统计,60%的财富1000企业雇佣了首席数据官(CDO),这个百分比在2012年仅为12%。且这一些企业在麦肯锡增长和利润研究报告里的表现远超他们的竞争对手。
更重要的是,数据(和数据系统)不仅直接给硅谷的科技公司带来了收益,也让传统产业里的企业获益匪浅。

随着数据基础设施资源和市场的增长,其工具与最佳实践也在快速迭代。因此,目前很难得到这些不同模块组合在一起的统一看法,这也是我们完成这篇文章的初衷,希望能给大家输出一些有价值的观点。
我们与一些主流数据组织的从业人员交流了以下问题:(a) 他们内部的技术栈构成;(b)如果他们从头开始搭建,架构是否会不同。这些讨论的结果形成了以下参考架构图:
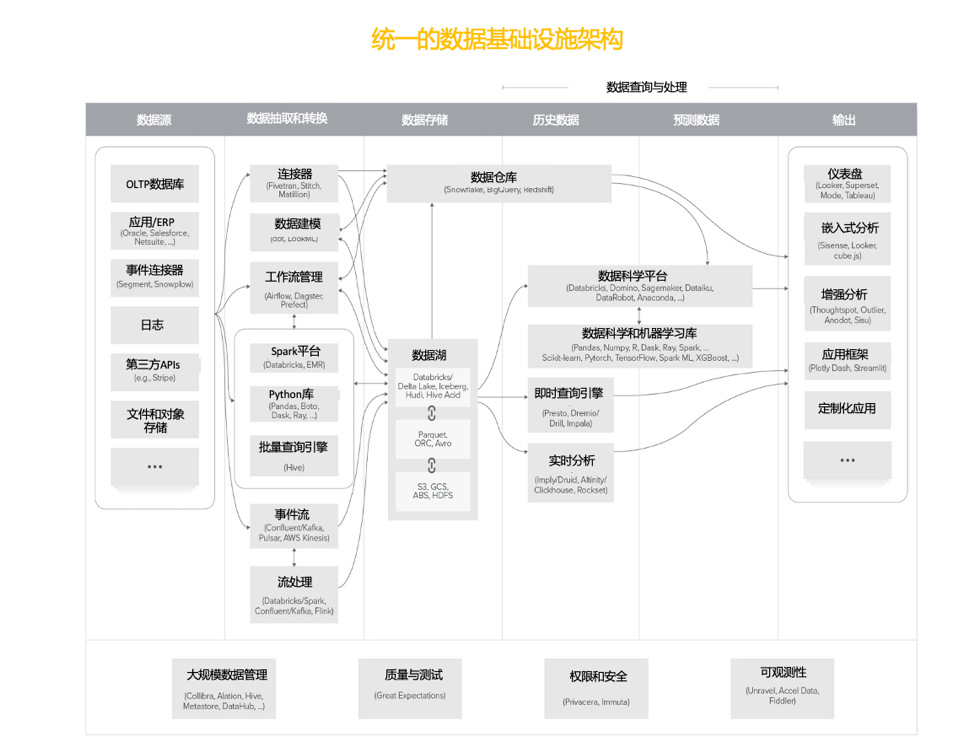
注:这里排除了交易系统、日志流程和SaaS分析应用关于架构图列的定义如下:
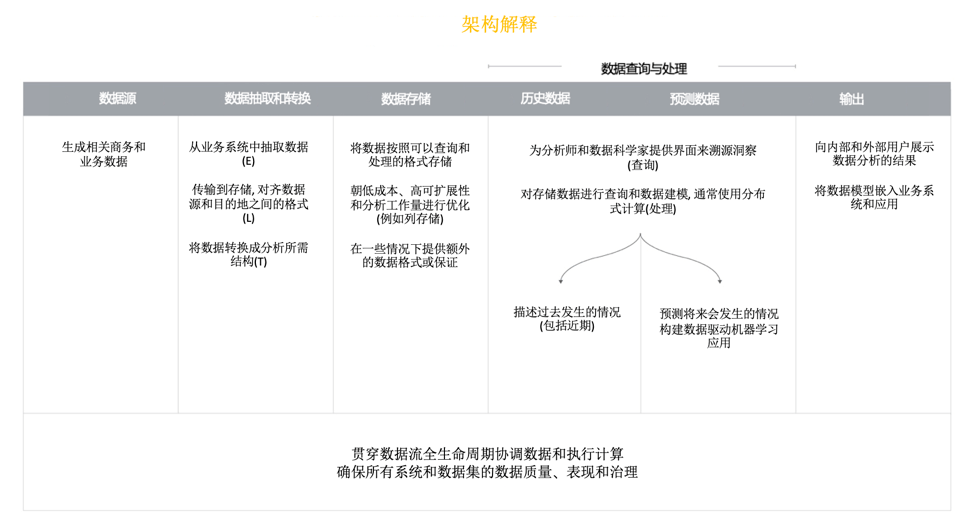
当然,这个架构仍然面临着很多新的变化,这些变化可能远超你能在多数别的产品系统中的发现。我们尝试总结了一个涵盖多数用户场景的统一架构。虽然最复杂的用户的架构可能接近这个,但大多数真实的情况都要比统一架构简单。
数据基础设施一般服务于两个重要的目的:通过数据(分析用户案例)帮助业务负责人更好地做决策;和通过机器学习(业务用户案例),建立面向客户应用的数据智能。
围绕这些广泛的用户案例已形成两个平行的生态。数据仓库成为分析系统的基础。大多数数据仓库以结构化的形式存储数据,其设计目标就是能用SQL快速、简单地从核心业务指标中提炼出有用的观点(尽管Python已经越来越流行)。而数据湖是业务系统的核心。数据湖允许以数据原始形式存储数据,为更高级的数据处理需求提供了灵活性、规模性和高性能。数据湖能够最终靠Java/Scala, Python, R和SQL等多种语言调用。
这其中的每一项技术都有非常忠实的支持者。围绕其中任意一种进行构建都会对剩下的技术栈产生重大的影响(后续会详细的介绍)。但有趣的是,现代数据仓库和数据湖开始越来越相似——都提供数据存储、原生集群扩展、支持半结构化的数据类型、ACID交易、交互式SQL查询等。
一个核心问题来了:数据仓库和数据湖是否正在走向融合?或者换个说法,他们在数据技术栈中的位置是不是能够互换?一些专家觉得这个趋势正在发生,技术和供应商格局正在发生简化。另一些专家觉得由于语言、用户场景、和其他因素均存在一定的差异,目前这样平行的生态将会持续下去。
数据基础设施受整个软件行业的架构变化的影响,包括云化、开源、SaaS商业模式等等。然而,除此以外,也有一些数据基础设施本身独有的变化。这些变化正推动架构向前发展,而且过程中经常给市场带来不确定性(例如ETL工具)。
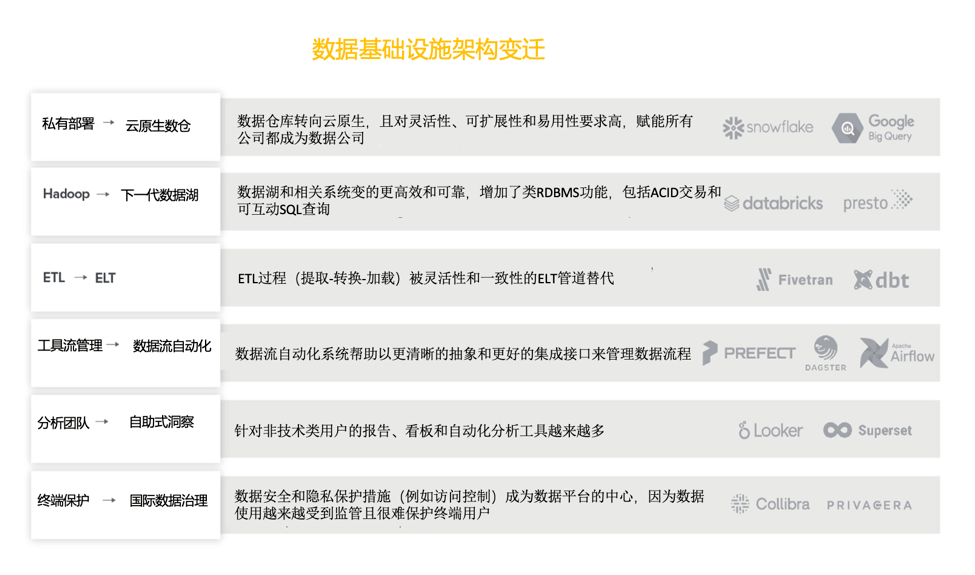
全新的数据能力必将带来与之匹配的全新的工具和核心系统,这些趋势正在从零开始创造新的技术类别和市场。

为了提高架构的可行性,我们让专家编写了一份通用的 架构图 -- 基于规模、复杂性和目标用户场景与应用的数据组织架构实施指南。
我们将和大家伙儿一起来分享三种概述性的通用架构图:首先是现代商业智能, 专注云原生数据仓库和分析的使用场景;第二种,着眼于 多模型数据处理,涵盖既包括分析又包括业务场景的情况;最后一种架构,我们放大了业务系统和 AI与机器学习 的新场景。
适合所有公司类型的云原生商业智能—简单易用,试用成本低,比过去的数据仓库更具可扩展性。
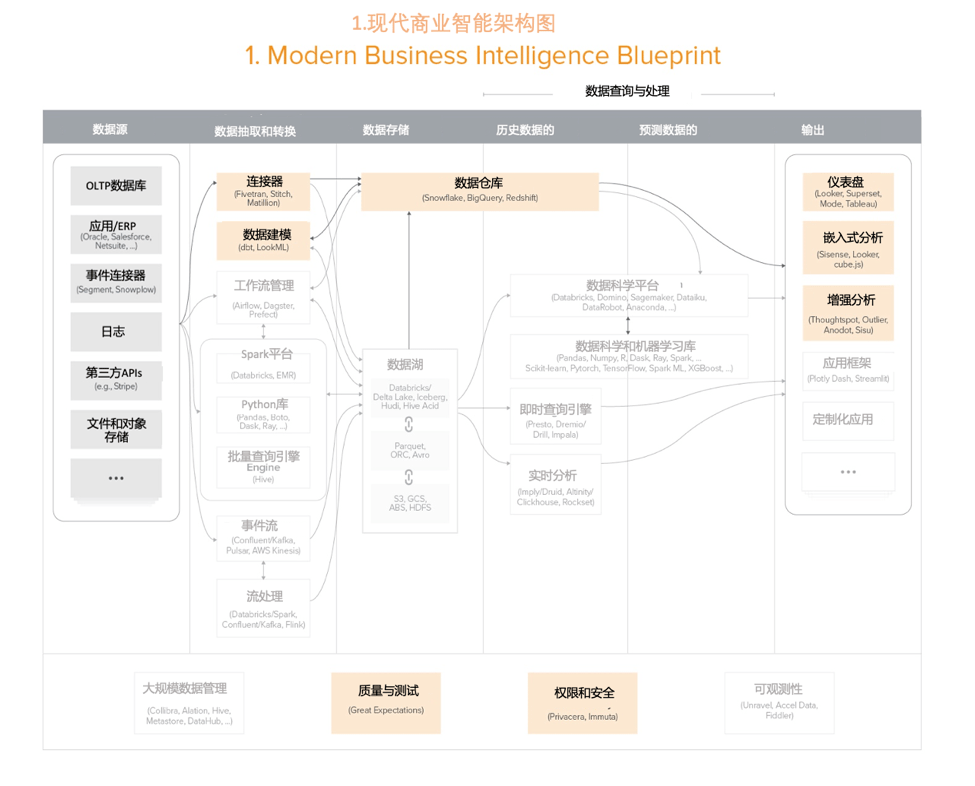
对于数据团队和预算比较小的公司来说,该架构越来越成为一个默认选项。更多企业也从传统的数据仓库迁移到这个架构上来,以便更好地利用云的灵活性和可扩展性。
核心用户场景包括报告、仪表盘和实时分析,主要使用SQL(和一些Python)来分析结构化数据。
这个模式的优势包括前期投入低、快速、容易上手、人才比较多。当然,这个架构对于数据需求复杂的团队,例如广义数据科学、机器学习,或是流数据/低延时的应用等,并不适用。
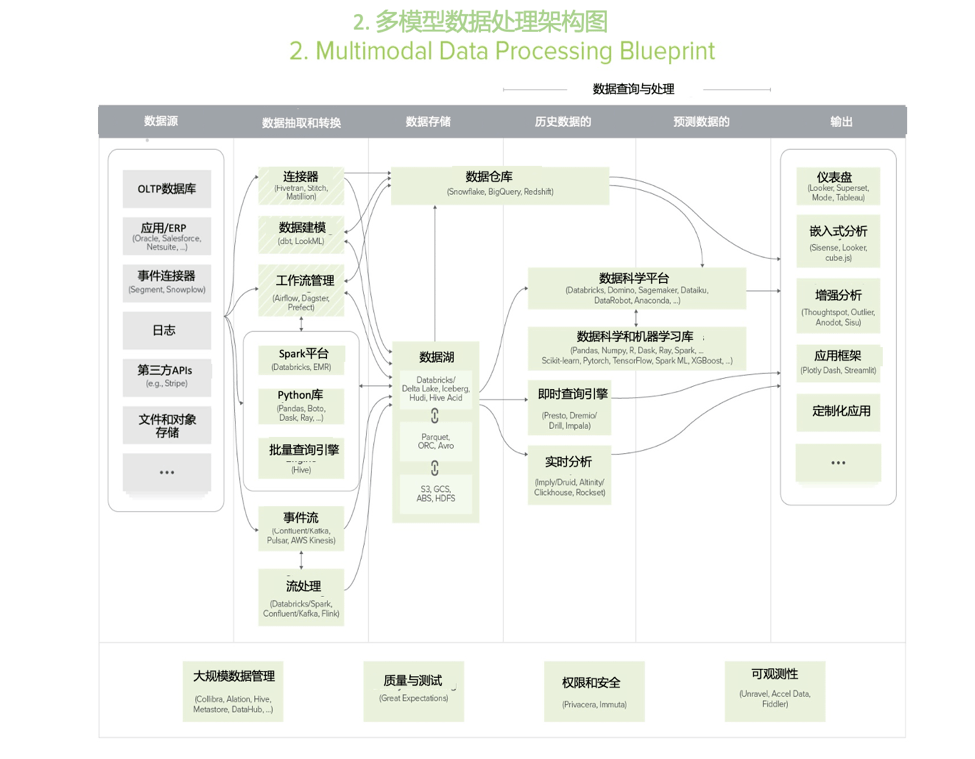
核心用户场景包括商业智能和更高级的功能——包括人工智能/机器学习、流数据/低延时分析、大规模数据转换和各种不同数据类型的处理(包括文字、图像和视频),且支持不同的编程语言(Java/Scala, Python, SQL)。
这种模式的优点是其灵活性,能支持各种应用、工具、用户自定义功能和部署,且对于大型数据集有成本优势。该架构不太适用于刚组件数据团队或者数据团队较小的公司。维护架构需要较多时间、成本和专业知识。
一个全新的、正在演进过程中的数据技术栈,能支持机器学习模型的开发、测试和运维。

多数从事机器学习的公司已在使用该模式中的部分子集。大型机器学习系统常常要实施以上完整的架构,或者依赖内部团队开发新的工具。
核心用户场景主要侧重于数据驱动的内部和面向客户的应用——在线运行(响应用户输入)或者批处理模式。
与预先定义的机器学习解决方案相比,这样的形式的优点是,完全掌控开发流程,为用户创造更大的价值,并将AI/机器学习构建为核心长期优势。该架构不太适合仅仅探索和测试机器学习,将其用于小规模的内部应用场景,或者主要依赖供应商的公司。大规模机器学习是现在最具挑战性的数据问题。
数据基础设施正在架构层面经历快速且根本性的变化。构建现代数据技术栈面临着各种各样且在持续不断的增加的工具选择。做正确的选择,比过去任何一个时间里都重要,因为我们将会持续的从纯粹基于代码的软件向代码和数据相结合的系统来进行转化。有效的数据能力现在是各行各业优秀公司的法码,并且数据能力将会帮助公司持续提升竞争壁垒。
我们希望借由这篇文章帮助数据从业者了解当前的技术状态,为公司的需求选择最合适的架构,并在该领域的持续发展中规划未来。